


Sommaire
- Le 6 Sigma et l'Excellence Opérationnelle. Juste du bon sens ?
- Combien de valeurs sont nécessaires pour avoir un échantillon représentatif ?
- Exploiter la donnée pour optimiser le pilotage d'un procédé
- Statistical modeling: The need for a reliable approach to improve process knowledge and understanding
- Bayesian approach in cosmetical research : Application to a meta-analysis on the anti-pigmenting effect of vitamin C
- Comparabilité, équivalence, similarité... Comment les statistiques peuvent nous aider à en faire la démonstration. Et bientôt la fin d'un "blind test" pour les autorités de santé et les industriels
- Le maintien du statut validé, une étape du cycle de validation
- Stratégie de validation des procédés et mise en application de l'Annexe 15 des BPF et des guidances FDA. Vérification continue des procédés (CPV)
De plus en plus d’outils, d’équipement, de capteur… sont en place pour générer de la donnée. Ces données permettent de créer de l’information et de la connaissance, qui sont extrêmement riches et bénéfiques pour les entreprises qui se donnent les moyens de les exploiter !

Un projet d’exploitation des données a été mené par Sanofi afin d’affiner le procédé de fabrication d’un antibiotique dans lequel un phénomène d’émulsion est observé. Grâce à l’analyse des données, le phénomène d’émulsion a été compris et mieux maîtrisé, et un gain de productivité a été constaté. Cet exemple est une belle illustration d’amélioration continue, qui a été visible et bénéfique pour tous les acteurs du projet.
1. Présentation du site et du projet
Le site SANOFI de Saint-Aubin-Lès-Elbeuf est spécialisé dans la production de molécules par voie de fermentation en grand volume à destination de clients interne (antibiotique, milieu enzymatique) et externe (vitamine) des industries de Santé.
Deux grands secteurs se distinguent sur ce site : la fermentation, en charge de la production des molécules d’intérêt ; l’extraction, en charge de l’isolement et de la purification de ces molécules à partir des mouts de fermentation. Les équipements (hors Utilités) sont dédiés par produit. Chaque atelier pilote ses procédés avec des systèmes de supervision centralisés dont les données sont historisées. Les ateliers et leurs fournisseurs internes sont coordonnés mais indépendants, leurs données sont donc captées sur différents supports.
Dans le cas de l’antibiotique, les molécules d’intérêt sont produites par fermentation dans un atelier, puis le mout est transféré dans l’atelier suivant pour isoler les molécules d’intérêt de la matrice de fermentation. Le produit d’abord filtré subit une extraction liquide-liquide pour migrer les molécules de la phase aqueuse vers une phase organique. Une fois en phase organique, il est aisé de concentrer puis de cristalliser le produit avant de le transférer vers d’autres étapes de traitement.
Lors de la mise en contact avec le solvant, il se forme une émulsion un peu comme une mayonnaise. Une partie de cette émulsion est entrainée dans les étapes en aval avant d’être éliminée, cela provoque une perte de productivité par encrassement et une perte de rendement par l’élimination de l’émulsion contenant du produit. C’est un phénomène connu, intrinsèque au procédé et celui-ci est conçu pour être piloté en tenant compte de cette émulsion. Cependant, dans une recherche d’amélioration continue et de performance accrue, cette émulsion est devenue une vraie problématique et un projet a été lancé afin de comprendre ce phénomène et de le maitriser au mieux.
2. Démarche
Pour étudier le phénomène d’émulsion, la démarche a débuté par la cartographie du procédé avec l’aide des principaux référents de ce produit et notre expert en analyse multivariée. L’ensemble des éléments entrants a été répertorié ainsi que l’ensemble des variables captées par les différents processus. Chaque donnée a été catégorisée selon sa nature et sa source.
Le recueil des données et la constitution de la base de données a été une étape essentielle du projet et certainement la plus chronophage. Les données sont générées et captées sous des formats multiples, et nécessite souvent l’implication de plusieurs acteurs.
En parallèle, la méthodologie à dérouler a été choisie, sous le regard éclairé de notre référent en statistique. L’approche retenue consiste à effectuer une première analyse en ACP (Analyse en Composantes Principales) permettant de décrire les données, suivie d’une PLS (Part Least Square ou régression des moindres carrés) permettant de d’étudier la correspondance entre les données (x) et une réponse choisie (y).
Le choix des réponses est une étape importante qui conditionne la durée nécessaire au traitement des données. En effet, chaque réponse est étudiée dans une analyse distincte afin d’identifier les paramètres influents qui lui sont propres. Bien sûr, les premières réponses identifiées sont celles qui présentent une spécification (teneur, rendement, volume, etc…) et viennent ensuite les réponses qui correspondent au confort de pilotage (valeur d’émulsion, temps de séjour de certaines étapes,…). Les réponses répondant à des spécifications sont souvent très resserrées sur une valeur dans un souci de fiabilité et reproductibilité et, de ce fait présentent une variabilité très limitée. La seconde population de réponses peut être plus intéressante car moins centrée sur une valeur cible et donc avec une variabilité permettant d’observer plus de nuances.
3. Constitution de la base de données
Le choix de la période sur laquelle les données ont été captées a été fait par rapport aux évolutions du procédé afin de garantir une homogénéité dans le pilotage de celui-ci. Comme on cherche à identifier des sources de variabilité, autant éliminer les variations déjà connues.
Une première problématique a été de redonner de la signification à des réponses dont les valeurs sont influencées par le pilotage de certaines étapes. Dans notre cas, l’émulsion est subie, sa valeur est utilisée pour piloter l’étape d’extraction liquide-liquide. Une valeur de 5 permet une bonne mise en contact des phases à cette étape ; mais la limitation de cette valeur est nécessaire pour éviter des phénomènes d’engorgement de la colonne et les aspects négatifs évoqués ci-avant. Cette limitation est réalisée en agissant sur les débits d’alimentation et la vitesse d’agitation. Ainsi, un jour où il y a plus d’émulsion, on observera une émulsion à 5 avec une agitation à 2 et une alimentation à 3. Et, a contrario, un jour avec moins d’émulsion, on aura une valeur à 5 mais avec une agitation à 8 et une alimentation à 9.
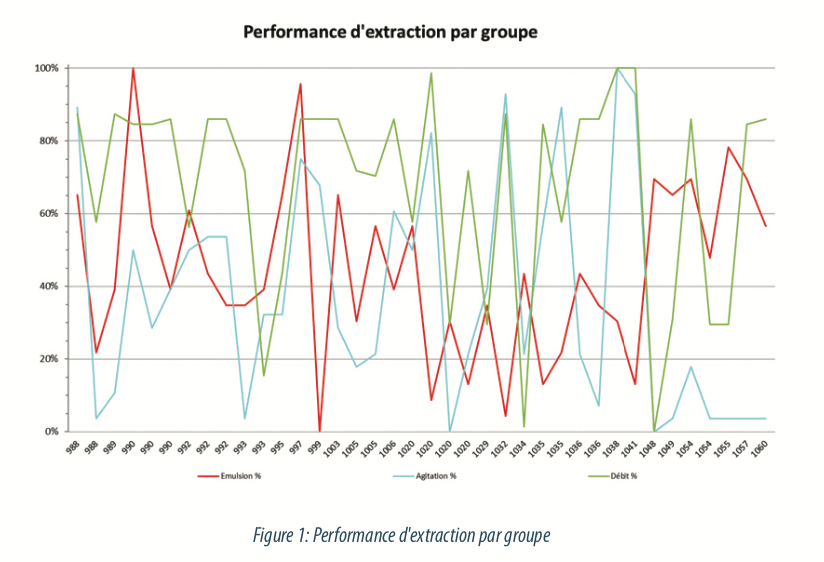
Bien sûr, il y a aussi des cas extrêmes où la valeur d’émulsion est au-delà de ce que le pilotage corrige et où on aura des valeurs de 2 ou de 8 mais ces cas sont trop rares pour ne baser l’étude que sur eux. Il a donc fallu créer un indicateur qui soit la résultante de ces trois paramètres et qui permette de coter le régime de fonctionnement de cette étape.
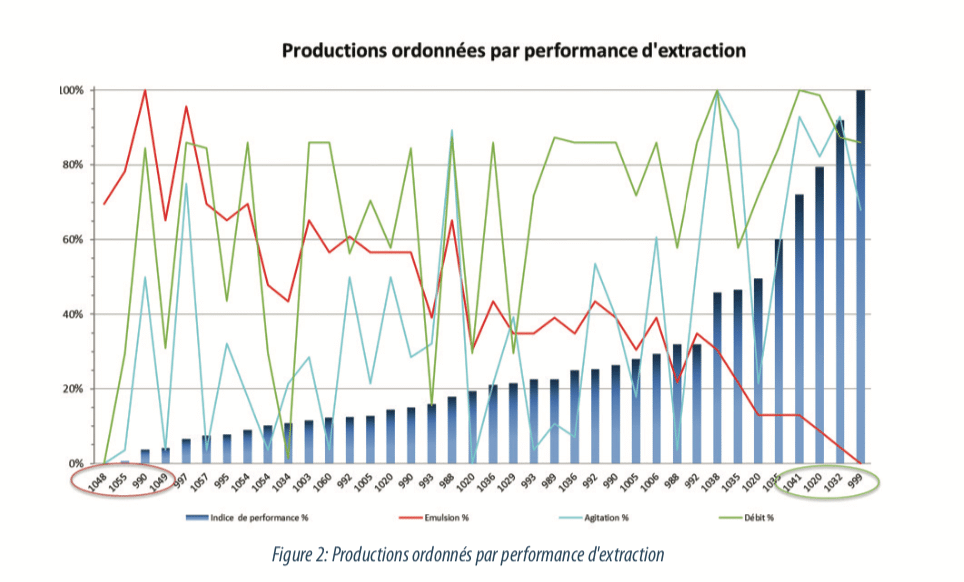
Une première liste des opérations de production a pu être établie avec une cotation du régime de fonctionnement, et ainsi déterminer les pires et les meilleurs cas sur la période d’étude. Quatre “bonnes” opérations et quatre “mauvaises” ont été choisies pour réaliser un premier jeu de données, tester nos méthodes de récupération de données et mesurer le temps nécessaire à ce captage.
Cet exercice de récupération a permis de juger de la facilité de récupération des données, de leur qualité, et du temps estimé pour les regrouper. En effet, l’exercice est très différent lorsqu’elles sont stockées informatiquement ou lorsqu’elles sont archivées dans une fiche de travail dans un registre de suivi.
De plus, un certain nombre de données est enregistré de façon dynamique, comme un profil de température ou de pression durant le cycle de fermentation. Une réflexion a été menée sur comment réduire ces flux de données à quelques valeurs caractéristiques et pertinentes qui résument correctement le déroulé d’un cycle et qui permettent de comparer des cycles aux autres. Contrairement à ce que l’on pourrait penser, ce n’est pas un exercice évident, car l’habitude est de comparer des valeurs “résultats” comme un poids de produit ou une concentration mais rarement de synthétiser une courbe de tendance à une ou deux valeurs. Cet exercice nous a également obligés à repenser les valeurs suivies en cours de production : devait-on utiliser une valeur de transfert de gaz à un jalon de temps, ou relever l’âge d’atteinte de cette valeur, ou calculer la pente de sa courbe, etc… Dans certains cas, des outils ont dû être créés afin de traiter les données brutes et isoler de façon fiable et répétable les paramètres retenus pour l’étude. Une fois cette première base de données réalisée, le temps nécessaire par unité (1 ligne de la base) a pu être quantifié. La taille de l’étude à mener a été déterminée avec les décideurs selon les effectifs disponibles et la date cible de rendu de l’étude.
Finalement, une base de données a été constituée regroupant 151 mesures d’émulsion avec 140 paramètres, après 4 mois de recueil d’information.
La base ainsi constituée était trop importante pour être analysée en une passe. Les projections graphiques des données étaient surchargées et donc il était donc difficile de prendre du recul vis à vis des valeurs mathématiques. La base a donc été scindée en trois reprenant les principaux groupes de données : une avec les données continues de fermentation, une avec les données discrètes de fermentation et la dernière avec les données d’extraction. Chacune de ces bases utilise les mêmes données de réponses préalablement choisies.
4. Analyses des bases
Les méthodes ACP et PLS permettent de révéler des corrélations dans des jeux de données qui n’en présentent pas toujours de façon évidente. Il est important, avant d’exploiter les bases, de contrôler que les données utilisées ne présentent ni de valeur atypique susceptible de forcer une corrélation, ni de corrélation déjà établie qui fausserait l’importance de paramètres.
Ci-dessous, des données illustrent ce concept : dans le graphique suivant, la présence d’une valeur atypique peut donner l’impression d’une très bonne corrélation (régression en bleu) et d’un lien fort entre deux paramètres. Or, le retrait de cette valeur atypique modifie le sens et la force de cette corrélation (régression orange).
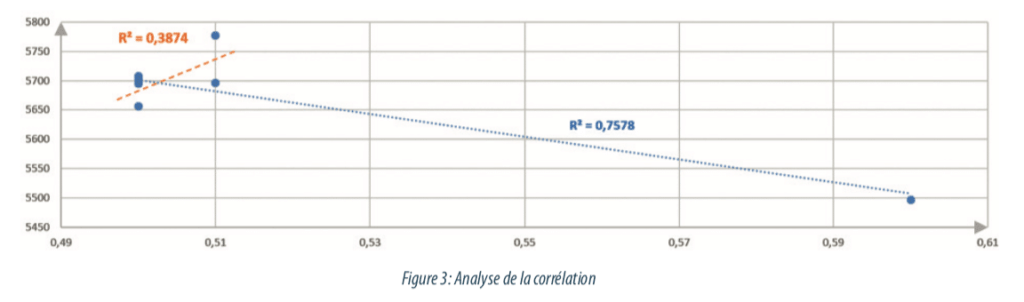
Sur chaque variable, une analyse univariée est lancée et un control de cohérence est effectué par le biais de boite à moustache (boxplot). Cet outil permet de visualiser les valeurs atypiques et de vérifier pour chacune s’il s’agit : d’une erreur de saisie, d’une valeur réelle mais correspondant à des conditions aberrantes de production ou s’il s’agit d’une valeur atypique mais pouvant être caractéristique d’une production en condition de routine.
Sur chaque base vérifiée, une analyse bi-variée est ensuite déroulée afin de contrôler les corrélations suspectées entre les variables deux à deux. C’est un moment important de l’étude, car au-delà de l’aspect préparatoire aux outils plus complexes, cette analyse permet de confirmer ou infirmer des relations pressenties par les équipes de production. C’est donc le moment de vérifier les a priori avec des données chiffrées et vérifiables, et de faire une première communication vers les opérationnels. L’intérêt de cette communication est aussi de présenter la différence entre des relations de causalité et des évènements concourants liés au rythme de production.
Après ces contrôles, l’analyse en composantes principales (ACP) peut être lancée. Elle permet de visualiser les corrélations entre les paramètres, mais également de refaire une évaluation des valeurs atypiques ; en effet, des valeurs peuvent se distinguer lors de l’ACP alors qu’elles n’étaient pas particulièrement mises en évidence lors des analyses univariées. Le but de l’ACP est de construire les axes d’un repère qui représentent au mieux les variations des données. En étudiant les axes, on évalue les liens entre les paramètres et on quantifie leurs importances. Le tri des VIP (Variable Importance in Projection) permet d’identifier les paramètres influents et ceux dont la variation n’a pas d’incidence sur les données.
A cette étape, il est possible d’identifier les relations de causalités entre les paramètres, au-delà de la problématique ciblée. En effet, l’analyse statistique permet de mettre en évidence la corrélation entre des paramètres. Cependant, cette corrélation peut avoir plusieurs raisons, et c’est en discutant avec les experts du procédé que l’on peut identifier les relations de “cause à effet” entre les paramètres corrélés.
L’ACP est donc une méthode descriptive permettant de visualiser la dispersion “naturelle” des données. Par la suite, une PLS est effectuée : la PLS est une méthode explicative permettant d’identifier les paramètres qui expliquent au mieux une réponse Y que l’on étudie, toujours à partir de nouveaux axes construits pour l’étude. Une première modélisation est lancée avec tous les paramètres : elle permet d’identifier les paramètres dont l’influence est négligeable sur la dispersion des données et qui peuvent être sortis de l’étude. Cette étape de tri permet de revoir la véracité de certaines idées reçues sur les influences des paramètres avec une réponse étudiée. Une fois la base réduite à ces paramètres influents essentiels, leur importance dans le procédé est mesurée.
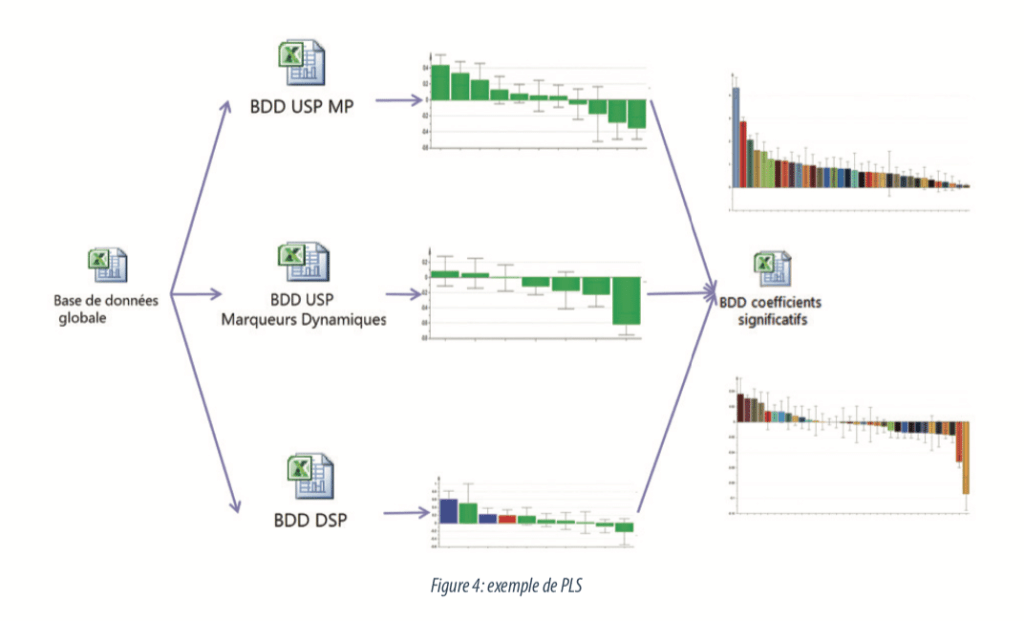
Cette démarche a été appliquée aux 3 bases, et pour chaque réponse. Ainsi, nous avons pu resserrer le domaine d’investigation sur quelques paramètres qui ont été rassemblés dans une base de données de synthèse (une pour chaque réponse). L’analyse de ces bases de synthèse ont permis de redonner une pondération entre les éléments retenus précédemment et d’évaluer quels paramètres sont, in fine, les plus pertinents, et comment ils influent sur chaque réponse.
5. Valorisation des résultats
Il n’y a pas de magie dans ces méthodes, la qualité des résultats obtenus dépend directement des données qui composent l’étude et parfois la vérité est ailleurs. En effet, certaines réponses ayant des spécifications n’ont pas été étudiées car elles étaient maîtrisées et donc peu variables… Or, certains paramètres de l’étude peuvent bien entendu les impacter. Il était important de mettre en évidence dans les conclusions de l’étude que l’ajustement de certains paramètres pour améliorer une réponse ne doit pas se faire au détriment d’une autre.
Dans notre cas, nous avons constaté également que les données sélectionnées dans cette étude n’expliquaient qu’une part limitée des phénomènes d’émulsion étudiés. Pour approfondir l’analyse, il faudrait donc replonger dans la définition des données à capter et s’interroger sur ce dont nous avons besoin mais que nous n’avons pas identifié à ce jour.
En revanche, sur la part expliquée de ces phénomènes, les leviers les plus influents ont été identifiés et ainsi des adaptations de modes de pilotage ont pu être proposées avec un argumentaire et des données quantifiées. En réinjectant les paramètres retenus en fin d’étude comme réponse dans les bases intermédiaires, nous avons pu constater les conséquences positives de leur modification et la qualité du pouvoir prédictif du modèle.
Par exemple, dans notre cas, l’habitude de pilotage était de réduire l’alimentation avant de réduire l’agitation pour limiter l’engorgement de la colonne en cas de poussée d’émulsion. L’étude nous a permis de démontrer qu’il fallait inverser cette pratique et que la perte de rendement (baisse d’agitation) était moins pénalisante que la perte de rythme (baisse du débit) sur la productivité globale de l’atelier.
Conclusion
Cette étude nous a apporté bien plus que de simples réponses à la problématique d’émulsion. Bien sûr, la mesure de l’influence des paramètres de pilotage sur ce phénomène a permis une meilleure réactivité dans les périodes de dérives. Mais, l’analyse des corrélations et l’identification de la non-influence d’autres paramètres nous ont également apportées un recul sur la connaissance que nous avions sur le procédé, ce qui participe grandement à sa maitrise.
Personnellement, je venais de rejoindre le site et l’équipe lorsque l’on m’a proposé de participer à ce chantier. Les questionnements, les recherches d’information et la visualisation des phénomènes liant les paramètres et les réponses m’ont permis d’avoir une connaissance du procédé et des acteurs du site avec lesquels j’aurai peut-être mis des années à acquérir dans une activité plus routinière. Je garde une satisfaction intacte de pouvoir continuer à appliquer ces méthodes en complément de l’analyse des procédés. Je reste prudent sur l’utilisation de ces méthodes et j’ai d’ailleurs une célèbre phrase du professeur et statisticien américain Aaron Levenstein affichée dans mon bureau: “Statistics are like a bikini. What they reveal is suggestive, but what they conceal is vital”
Il faut toujours garder un esprit critique et être guidé par le bon sens. Les chiffres seuls ne sont rien, leur interprétation éclairée est essentielle, et certaines analyses ne peuvent se faire qu’avec une bonne connaissance du domaine, une compréhension du sujet et du contexte de l’étude.
Partager l’article


Yann TUDAL – SANOFI
yann.tudal@sanofi.com
Acronymes
ACP : Analyse en Composantes Principales
PLS : Part Least Square
